Le sujet du versionnement et les erreurs induites par semver m’importe, ça n’a pas dû vous échapper depuis la publication du billet Oubliez ce que vous pensez savoir sur semver. C’est pour cette raison que j’ai repris la conception d’un outil que j’avais commencé il y a 5 ans : checkbreak. Comme je l’évoquais, le problème de semver est le défaut de connaissances du responsable de la release, qu’il soit théorique ou conjoncturel. C’est donc ce que checkbreak vise à palier : expliquer ce qu’est une rupture de compatibilité et où la trouver pour faciliter le versionnement.
Le point de départ de checkbreak est de mettre des mots techniques sur ce qu’est un changement incompatible : il s’agit d’une altération qui rompt le principe de Liskov d’un point d’entrée sur lui-même, ce point faisant partie de l’API publique.

Le programme se découpe donc en trois étapes distinctes :
- la collection,
- le parsage,
- l’analyse.
Passé ces trois étapes, l’outil vous affiche les changements qui sont susceptibles d’être des ruptures de compatibilités dans les fichiers changés.
NB : L’analyse statique étant par nature limitée à une compréhension réduite de la sémantique, il ne remplace pas le jugement humain. Charge à l’utilisateur d’exploiter cette mise en lumière pour passer en revue chacun des changements pour en définir la nature.
Voici un exemple sur le logiciel Mattermost :
\_app/config_test.go
| Function deletion:
- func TestConfigListener(*testing.T) ()
\_app/auto_responder.go
| Parameter adding:
- func (*App) DisableAutoResponder(string, bool) (*model.AppError)
+ func (*App) DisableAutoResponder(request.CTX, string, bool) (*model.AppError)
\_app/slashcommands/command_online.go
| Parameter re-typing:
- func (*OnlineProvider) DoCommand(*app.App, *request.Context, *model.CommandArgs, string) (*model.CommandResponse)
+ func (*OnlineProvider) DoCommand(*app.App, request.CTX, *model.CommandArgs, string) (*model.CommandResponse)
\_app/opentracing/opentracing_layer.go
| Result adding:
- func (*OpenTracingAppLayer) ClearChannelMembersCache(request.CTX, string) ()
+ func (*OpenTracingAppLayer) ClearChannelMembersCache(request.CTX, string) (error)
- func (*OpenTracingAppLayer) ClearTeamMembersCache(string) ()
+ func (*OpenTracingAppLayer) ClearTeamMembersCache(string) (error)
| Result re-typing:
- func (*OpenTracingAppLayer) GetPostsByIds([]string) ([]*model.Post, bool, *model.AppError)
+ func (*OpenTracingAppLayer) GetPostsByIds([]string) ([]*model.Post, int64, *model.AppError)
Détails techniques
Dans la première version, je m’étais basé sur l’unité « ligne » pour comparer les changements, presque comme une surcouche au diff. Je n’en ai jamais été pleinement satisfait car les langages sont permissifs sur la syntaxe, notamment les sauts de lignes. Je risquais donc de laisser passer certains patterns, et ainsi d’amoindrir l’intérêt de checkbreak.
Cette nouvelle version fut donc l’occasion d’améliorer la récolte et de passer sur une logique plus complexe mais plus fiable : l’arbre syntaxique du fichier (ou AST: Abstract Syntax Tree).
La collection
J’ai pris depuis le début le parti de m’appuyer sur git et tout ce qu’il considère comme une référence (commit, tag, branche),
c’est pour cette raison qu’il est possible de passer le même type de paramètres que pour un git diff.
Si l’utilisateur ne passe rien, les points de comparaison sont déduits : le point de départ est le dernier tag lexicographique et le point d’arrivée est HEAD.
À cette étape, les fichiers du diff récoltés sont les modifiés et supprimés (par construction d’une rupture de compatibilité). Puisque je vais devoir étudier les ASTs, je récupère donc chaque fichier deux fois - une fois par révision -, l’objectif étant d’avoir des données fiables à traiter dans les étapes suivantes.
Le parsage
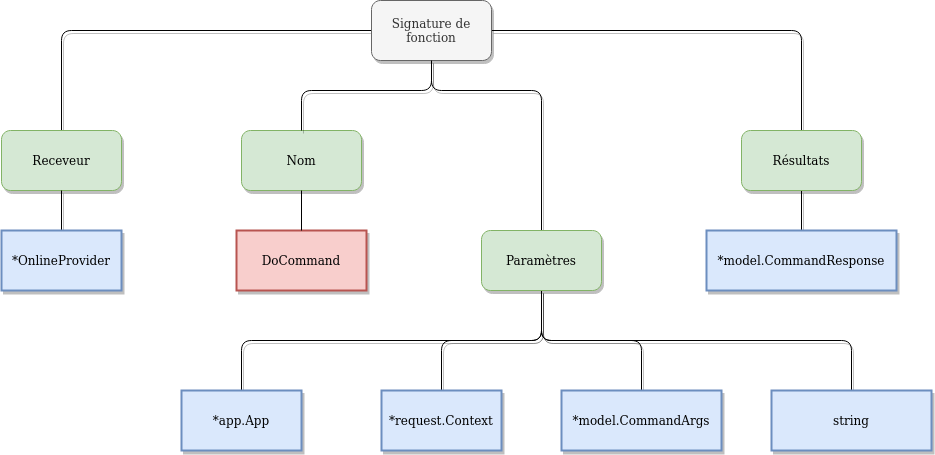
Cette étape est le vrai nerf de la guerre, car c’est l’objet de la refonte entre la v1 et la v2. Il s’agit là de découper le fichier et de reconnaître les fonctions publiques. Évidemment, il est nécessaire pour ça de comprendre le type de fichier dont on parle : j’ai visé la simplicité en m’appuyant sur l’extension, on verra si l’usage me donne raison. Cette connaissance du langage utilisé me donne accès au parseur dédié : forcément, chaque langage s’écrit différemment et il est nécessaire de découper le fichier en éléments atomiques spécifiques au langage pour reconnaître tel ou tel symbole.
C’est grâce à lui que je recompose la signature de chaque fonction publique et de tous ses attributs. La difficulté de cette étape est que ça demande une connaissance pointue du langage pour la construction de l’arbre : une méconnaissance d’une combinaison de tokens et la puissance de checkbreak tombe à l’eau. C’est pour cette raison que je me suis concentré sur mon langage de prédilection, Golang, pour traverser les principaux écueils plutôt que chercher tout de suite l’universalité.
Cette étape est faite pour les deux versions de fichiers, pour tous les fichiers récoltés.
L’analyse
Cette troisième étape est dédiée à la compréhension des différences entre les deux versions du fichier, normalisées par le parser. La liste des changements incompatibles est connue donc je passe chaque fichier à travers toutes les spécifications de changements : s’il en satisfait une, je le ventile dans la bonne case. Finalement, même si ça devrait être la vraie puissance de checkbreak, cette étape est la plus facile grâce au travail réalisé par les étapes précédentes. C’est même la seule qui ne tire pas profit de la concurrence, c’est inutile.
Benchmarks
Une fois que j’ai eu mon découpage logique, je me suis attelé à vérifier les performances. J’ai commencé simple : un timer fin - début. Les premiers tests montraient que le système tenait environ 100 fichiers mais pas plus. Dommage quand on veut comparer des versions majeures de logiciel. Une optimisation simple consistait à supprimer une dépendance à une librairie et un sous-shell (coucou @Thomas !), ça m’a fait gagner 10s pour 100 fichiers. J’ai donc mis la barre plus haut en visant un changement de 200 fichiers. Pour cela, j’ai pris le logiciel Mattermost comme base de travail : il y a énormément de fichiers, tous en go, pile ce qu’il me fallait !
Pour garantir des durées de traitement raisonnables, cette densité de fichiers m’a obligé à utiliser la killer feature de Golang: la concurrence. Ainsi, en lieu et place d’un traitement séquentiel fichier après fichier, chaque fichier est traité en concurrence des autres. Grâce à cela, checkbreak peut collecter, parser et analyser 464 fichiers en moins de 1s !
Pour la suite ?
Plusieurs défis m’attendent pour la suite de checkbreak. Tout d’abord, je voudrais ajouter d’autres langages pour servir plus d’utilisateurs. Je vais devoir pour cela créer de toute pièce des parsers de langage vu que ça n’existe pas à cette heure. J’aimerai également mieux comprendre le diff récolté : je voudrais appliquer l’algorithme de Myers pour vraiment mettre en lumière dans le rapporteur ce qui a changé. Restreindre la recherche à l’API publique uniquement serait aussi une bonne fonctionnalité.
Enfin, le plus grand challenge est de faire utiliser l’outil pour le confronter aux usages et vérifier son adéquation.
Quels que soient ces défis, tout aide est la bienvenue. Checkbreak est sous licence GPL3 donc je vous invite vraiment à vous l’approprier, ou à minima y jeter un coup d’œil et me faire un retour sur mon Linkedin. Toute critique est bonne à prendre.
Source: