Comme gestionnaire de conteneurs, Portainer est un outil très pratique. En présentant une interface graphique agréable à l’œil, il permet à des équipes non techniques de consulter et d’influencer des piles logicielles conteneurisées. Pour les techniciens, ce genre d’outil garantit l’acceptabilité de la solution « conteneur » et, in fine, facilite l’adoption de la méthode DevOps. Mais son pilotage des cycles de vie des logiciels via GUI nous condamne-t-il à sacrifier la gestion via la ligne de commande ?
Portainer s’installe comme un conteneur Docker et, comme on peut s’y attendre, cela passe par quelques commandes1 exécutées sur le nœud contrôleur :
$ docker volume create portainer_data
$ docker run -d -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock \
-v portainer_data:/data portainer/portainer-ce:2.19.4-alpine
Ensuite, l’utilisation en vitesse de croisière passe par l’interface graphique, elle sert précisément à ça. Mais ces manipulations futures ont un défaut majeur : elles manquent d’automatisation. Or, sans automatisation2, les coûts globaux de manipulations sont linéaires au nombre de piles et on ne profite pas non plus de la répétition pour améliorer la fiabilité. Nous devons trouver une façon programmable d’interagir avec l’outil : une API. Et ça tombe bien, Portainer en fournit une3.
Autour de quoi tourne la gestion courante technique de Portainer ? Assez peu d’opérations finalement, toutes sur une pile logicielle :
- création,
- (re)configuration,
- mise à jour (de la pile exécutée).
Si nous voulons instrumentaliser Portainer, nous devons traduire ces instructions en requêtes HTTP. Mais avant ça, il y a un problème : comment s’authentifier sans utilisateur ?
Initialisation
À l’initialisation du logiciel, Portainer nous demande de créer un administrateur. Bien que l’on pourrait gérer ce cas particulier en graphique, on va viser une automatisation complète.
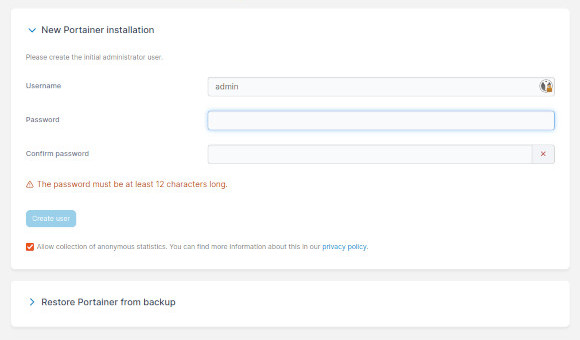
Pour commencer, on va constater la même chose via la CLI :
$ curl -k https://localhost:9443/api/users/admin/check
{"message":"No administrator account found inside the database","details":"object not found inside the database"}
Créons notre administrateur initial avec la requête ad hoc :
$ curl -X POST -k https://localhost:9443/api/users/admin/init -d '{"password": "Y55XGoAAey9PahKHAIvW", "username": "admin"}'
{"Id":1,"Username":"admin","Password":"$2a$10$OrLjfimzDGDHDEeUv00vEO8PK8b1NRKpU2UVhiU.aaSWy5Wy7LFHS","Role":1,"TokenIssueAt":0,"ThemeSettings":{"color":""},"UserTheme":"","PortainerAuthorizations":null,"EndpointAuthorizations":null}
Pour confirmer le succès de l’opération, nous pouvons aussi répéter la vérification initiale :
$ curl -kI https://localhost:9443/api/users/admin/check
HTTP/1.1 204 No Content
[...]
Cette initialisation étant faite, passons à notre pile.
Au quotidien
La plupart des manipulations permises par l’API requièrent une autorisation, nous devons donc commencer par nous authentifier :
$ curl -k -X POST https://localhost:9443/api/auth -d '{"password": "Y55XGoAAey9PahKHAIvW", "username": "admin"}'
{"jwt":"eyJhb[...]3XEo"}
Cette route d’authentification nous renvoie un JWT que l’on devrait passer en header de toutes requêtes sensibles. Ce token est valable 8h, largement suffisant pour notre usage.
Pour la suite, il faut comprendre que Portainer est versatile. Il permet de se connecter à plusieurs fournisseurs (Docker ou Kubernetes), mais il fonctionne également par contexte d’exécution, ou environnement. De cette façon, il est possible à partir d’un même serveur de manipuler diverses situations : locale, distante via le réseau ou en edge.
Notre cycle de vie travaillera dans un contexte spécifique, c’est pourquoi il faut commencer par créer un environnement :
$ curl -ki -H 'Authorization: Bearer eyJhb[...]3XEo' https://localhost:9443/api/endpoints -F Name=local -F EndpointCreationType=1
$ curl -k -H 'Authorization: Bearer eyJhb[...]3XEo' https://localhost:9443/api/endpoints \
| jq '[.[] | with_entries(select(.key | in({"Id":1, "Name":1, "Type":1, "URL":1})))]'
[
{
"Id": 2,
"Name": "local",
"Type": 1,
"URL": "unix:///var/run/docker.sock"
}
]
NB: la sortie est conséquente, il vaut mieux filter les infos utiles
Maintenant nous pouvons nous occuper de nos piles. Nous allons donc créer une pile de type “repository” sur le endpoint 2. Sa configuration minimale est décrite dans le fichier stack.json suivant :
{
"name": "myAwesomeStack",
"repositoryReferenceName": "refs/heads/master",
"repositoryURL": "https://github.com/docker/awesome-compose",
"tlsskipVerify": false,
"autoUpdate": {
"forcePullImage": false,
"forceUpdate": false,
"interval": "10m"
},
"composeFile": "wordpress-mysql/compose.yaml",
"additionalFiles": [],
"env": [
{
"name": "name",
"value": "value"
}
]
}
$ curl -ki -H 'Authorization: Bearer eyJhb[...]3XEo' -H 'Content-Type: application/json' https://localhost:9443/api/stacks/create/standalone/repository?endpointId=2 --data @stack.json
HTTP/1.1 200 OK
[...]
On peut le confirmer via le navigateur sur http://localhost, notre pile a bien été créée et a automatiquement démarré !
Il nous reste deux opérations : la reconfiguration et le redéploiement. La première est ni plus ni moins qu’une extension de la création. Si les éléments essentiels de la pile ne changent pas (nom, URL et fichiers descripteurs), le reste est libre :
$ curl -ki -H 'Authorization: Bearer eyJhb[...]3XEo' https://localhost:9443/api/stacks/2/git?endpointId=2 -d '{"autoUpdate": {"interval": "5m"}, "env":[{"name": "name2", "value": "value2"}]}'
HTTP/1.1 200 OK
[...]
Le redéploiement quant à lui s’effectue de la façon suivante :
$ curl -ki -X PUT -H 'Authorization: Bearer eyJhb[...]3XEo' -H 'Content-Type: application/json' https://localhost:9443/api/stacks/2/git/redeploy?endpointId=2 -d '{}'
HTTP/1.1 200 OK
[...]
Conclusion
Ici, nous avons automatisé les tâches quotidiennes de gestion d’une pile logicielle, mais il y a encore bien d’autres opérations possibles. De plus, grâce au type “repository”, nous nous approchons de la méthode GitOps et nous permettons au logiciel de se mettre à jour automatiquement. Cette méthode et son intérêt seront détaillés dans un prochain billet.
La versatilité de Portainer est une force, elle permet de rassembler autour de l’outil diverses populations, chacune pouvant interagir avec la vue qui lui convient le mieux. Tout cela grâce à l’API. Après l’avoir bien utilisé, j’ai aujourd’hui du recul sur son usage et je conseille de le mettre en place pour les profanes, sur des rôles de consultation ou pour quelques tâches annexes. L’administration par contre doit rester la plus automatisée possible via des moyens programmables, vecteurs d’automatisation et de contrôle. C’est le seul moyen de passer à l’échelle.
Comme d’habitude, vous pouvez retrouver le code pour essayer par vous-même sur le dépôt d’exemple.