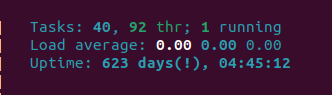
Fils spirituel du bien connu top, htop est ergonomiquement plus abouti : il y a de la couleur, il est possible de scroller, la présentation est moins austère et l’outil possède tout un tas d’options facilement accessibles. Un outil bien utile pour tout sysadmin. Mais un mystère réside : sur certains systèmes on peut observer dans l’en-tête un « ! » après le nombre de jours de l’uptime. Que peut bien signifier cette information et qu’est-ce que ça dit de nos pratiques ?
htop est un logiciel libre, son code est donc auditable ce qui nous permet de connaître les conditions de présence du « ! » :
| |
Ce code du commit 52486dbc est limpide, le point d’exclamation apparaît lorsque le nombre de jours de l’uptime dépasse les 100 jours. Ce que nous ne savons pas en revanche, c’est pourquoi cette condition existe, et aussi loin qu’on puisse remonter (le commit d6231bab de la 0.6.1), il n’y a aucune explication sur cette condition.
Nous ne trouverons pas la raison dans le code, mais heureusement le mainteneur principal a répondu à cette interrogation sur StackOverflow en 2017 :
La raison n’a rien d’extraordinaire, c’est juste un œuf de Pâques dans le logiciel. Considérez que le programme est impressionné par votre temps de disponibilité, et prenez-le comme vous le voulez :)
~ Hisham Muhammad1
Si le créateur de l’outil ne semble pas avoir eu d’intention particulière avec ce « ! », nous pouvons malgré tout nous appuyer sur le contexte pour donner une signification précise et porteuse d’information. Pour cela, posons-nous la question : quel service le serveur rend-il et dans quel but ?
C’est quoi l’uptime ?
L’uptime mesure le temps depuis lequel le système est allumé, on l’obtient sous GNU/Linux via la commande uptime ou w. De premier abord il pourrait s’agir de ce qu’on appelle une “vanity metric”, autrement dit un indicateur qui nous rempli d’orgueil (i.e. « c’est moi qui aie le plus gros uptime », on trouve d’ailleurs des défenseurs de cette quête sur Reddit2), mais il est important de comprendre d’où cette donnée tire sa valeur.
La disponibilité est l’un des critères de la qualité d’un service, elle dépend de l’hébergeur, mais surtout de l’infrastructure et de la topologie réseau que nous avons mis en place. Seulement voilà, les ordinateurs ont longtemps coûté très cher, tant en CPU3 qu’en mémoire4, poussant les solutions techniques à adopter une architecture « simple », avec peu de serveurs.
En conséquence, il fallait prendre soin des serveurs pour garantir la continuité du service et puisqu’ils étaient spécialisés et uniques, chaque serveur était important ; en perdre un signifiait perdre le service entier. L’uptime était donc le symbole d’une qualité de service, avec un couplage fort entre la disponibilité du service et celle du serveur.
Éviter le piège de l’uptime serveur
Aussi compréhensible soit-il, ce couplage est un piège. Pourquoi ? Parce que ce n’est qu’une question de profondeur, tôt ou tard un serveur est physique, il possède donc une disponibilité maximale infranchissable et cette dernière décroît avec l’âge du serveur5. Autrement dit : on peut perdre un serveur, et en fait, on va perdre un serveur, la question c’est juste quand. Est-ce que cela doit forcément dégrader la qualité générale du service ?
Le risque de perdre un serveur est donc bien réel. Mais quel est-il ? En premier lieu, c’est un risque de sécurité puisque certains correctifs ou les montées de versions ne peuvent s’appliquer qu’au redémarrage du système. Ensuite, c’est un risque de performance dû aux optimisations logicielles et matérielles dont on ne profitera pas. Enfin, c’est paradoxalement un risque de disponibilité car le manque de préparation à la coupure nous désorganise, nous fait faire des erreurs, ou nous oblige à corriger les ruptures de compatibilité, le tout dans l’urgence.
L’approche Cattle VS Pet6 cherche à palier à ça : les serveurs ne sont plus des animaux de compagnie, importants, uniques et traités avec soin, mais un troupeau d’éléments différenciés mais sans identité propre. En embrassant l’idée que le serveur peut à tout moment être remplacé, on se prépare à ce qui va inexorablement arriver, soit pour en réduire le coût (automatisation), soit pour en annuler l’impact (réplication).
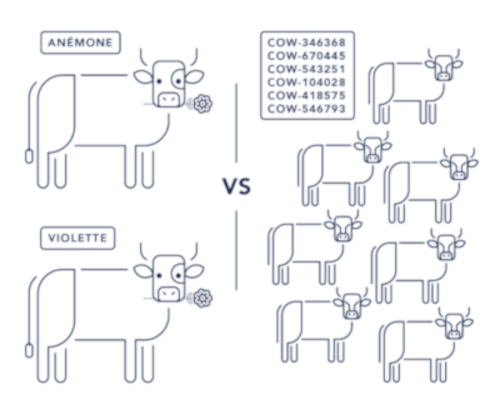
Pour arriver à nos fins, il est nécessaire d’utiliser l’infra as code pour structurer et formaliser l’état final souhaité d’un serveur. Il ne s’agit pas seulement de documentation après coup, mais bien de construire l’infrastructure par cette pratique ; l’infra as code devient la source unique de vérité de ce qu’est et fait le serveur, et tout ce qui est décrit à côté doit être considéré comme volatile. Son usage participe à l’application du mouvement DevOps et grâce à ça, nous pouvons très fréquemment éteindre et redémarrer nos serveurs. Ou mieux encore, les détruire et les reconstruire !
La vraie information fournie par ce point d’exclamation

Alors, de quoi ce point d’exclamation est-il le nom ? De la peur et cette peur provient un manque de contrôle. Or il est de notre responsabilité, au nom de la bonne qualité de service, d’avoir une maîtrise fine de nos environnements d’exploitation. La virtualisation, l’infra as code, le cloud et le mouvement DevOps sont justement là pour adresser ce sujet ; ce point d’exclamation est donc là comme une alerte7 nous invitant chaque jour à nous mettre à ces pratiques, avant que la catastrophe arrive.
La disponibilité, ce n’est pas empêcher nos serveurs de tomber, c’est leur permettre de tomber et que ça ne soit pas grave.
https://ourworldindata.org/grapher/historical-cost-of-computer-memory-and-storage ↩︎
https://www.statista.com/statistics/430769/annual-failure-rates-of-servers/ ↩︎
https://erp.today/pets-vs-cattle-2-0-an-analogy-and-approach-for-modern-infrastructures/ ↩︎
https://archive.org/details/alert-metal-gear-solid_202209 ↩︎